Análisis de Residuales
1. ¿ Qué son los residuales?
Es la diferencia entre el valor real y el valor proyectado de nuestro modelo de regresión.

ri = Residual
Yi= Valor real

= Valor proyectado
El modelo es adecuado cuando el valor de los residuales es en promedio cercano a cero (0). En otras la palabras nuestra proyección es precisa.
2. ¿ Para qué se utiliza el análisis de residuales?
El análisis de residuales nos ayuda a :
a) Verificar la normalidad de los residuales.
Es decir verificar si los residuales siguen una distribución normal con una media de cero.
b) Verificar la homogeneidad de las varianzas.
c) Detectar la presencia de Outliers (Puntos alejados del rango de dispersión de datos)
d) Determinar la independencia de errores u observaciones
Es decir descartar la existencia de una relación de dependencia de los residuales.
3. Ejemplo de Análisis de Residuales
Se va a desarrollar la siguiente casuística para verificar la normalidad de los residuos utilizando el programa SPSS.
De acuerdo a los resultados obtenidos se realizará el análisis e interpretación de la información.

El Gerente de Marketing de una cadena de supermercados desea utilizar el espacio en los anaqueles para predecir las ventas de comida para mascotas. Una muestra aleatoria de doce (12) tiendas de igual tamaño son seleccionadas, con los siguientes resultados:

- En primer lugar ingresamos los datos al programa SPSS tal como se muestra en la siguiente figura:

- Luego seleccionar la opción Analizar >> Regresión >> Lineales ...

- Seleccionar "Venta Semanal" como variable dependiente y "Espacio" como variable independiente tal como se muestra:

- Seleccionar el botón gráficos y activar con un check las opciones "histograma", "Gráfico de prob. normal" ," Generar todos los gráficos parciales" y hacer clic en el botón continuar:

- Hacer clic en el botón "Guardar" , activar con un check la opción de residuos " No estandarizados" ,desactivar la opción de "Incluir matriz de covarianzas" y hacer clic en el botón continuar:

- Hacer clic en el botón Aceptar y se mostrará la siguiente reportería:

Podemos observar en la estadística de residuos que la media del residuo es cero (0). Este valor es relevante para nuestro modelo. Dado que deseamos predecir las ventas con un margen mínimo de error.

En el gráfico P-P normal de regresión Residuo estandarizado, podemos observar que aparentemente los residuos calzan o están cercanos al modelo.

Sin embargo para poder afirmar con certeza de que los residuos del modelo siguen una distribución normal con media cero (0) se realizará un análisis riguroso:
3.1 Verificación de la normalidad de los residuos
En este caso se utilizaran dos (02) pruebas:
La prueba de Kolgomorov-Smirnov
La prueba de Shapiro-Wilk
a) Prueba de Kolgomorov
- Para realizar esta prueba de bondad, seleccionar la opción Analizar >> Pruebas no paramétricas >> Una muestra

- En la ventana emergente, seleccionar la pestaña Campos, y en la sección de campos agregar las variables del modelo tal como se muestra en la siguiente figura:

- En la pestaña Configuración, hacer clic en Personalizar Pruebas y activar con un check la prueba de Kolgomorov tal como se muestra:

- Hacer clic en el botón de Opciones de la prueba de Kolgomorov, luego activar con un check la opción " Normal" y hacer clic en el botón Aceptar

- Finalmente hacer clic en el botón Ejecutar y se mostrará el siguiente resultado.

Interpretación: De acuerdo al resultado según la prueba de Kolgomorov, el modelo es consistente por lo que se acepta que los residuales siguen una distribución normal con media cero (0).
b) Prueba de Shapiro - Wilk
- Hacer clic en la opción Analizar>> Estadísticos Descriptivos >> Explorar

- Seleccionar la variable a analizar , en nuestro caso los residuales tal como se muestra:

- Luego hacer clic en el botón Gráficos,activar con un check la opción Gráficos de normalidad con pruebas y hacer clic en el botón continuar:
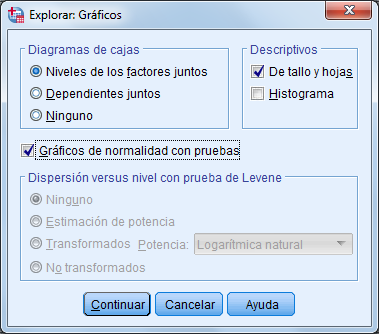
- Finalmente hacer clic en Aceptar y mostrará los siguiente resultados:

Como se puede apreciar el reporte nos brinda los resultados tanto de la prueba de Kolgomorov como la prueba de Shapiro-Wilk.
Interpretación: El resultado de la prueba de Shapiro Wilk es 0.231. Considerando que la prueba tiene un nivel de significancia (alpha) de 0.05.
- Si el resultados es menor a 0.05 , se afirma que los residuales no siguen una distribución normal.
- Si por el contrario el resultado es mayor a 0.05 , se afirma que los residuales siguen una distribución normal.
Para nuestro caso el valor obtenido de la prueba de bondad es 0.231 , el cual es mayor a 0.05, por tanto podemos afirmar que el modelo es consistente y los residuales son cercanos a cero.
Conclusíón: Se comprueba la normalidad de los residuos a través de las pruebas de bondad de Kolgomorov y Shapiro-Wilk. Los residuos siguen una distribución normal con media cero (0).

































